摘要
在开发过程中,很有可能会遇到这样的情况,服务端返回的是html的内容,但需要在客户端显示纯文本内容,这时候就需要解析这些html,拿到里面的纯文本。达到这样的目的可以有很多途径,比如自己写正则表达式,但对于没有什么规则的内容,就有点力不从心了。Html Agility Pack开源组件,可以通过xPath的方式快速的解析html内容。
一个例子
组件网址: ,你可以通过Nuget进行安装。
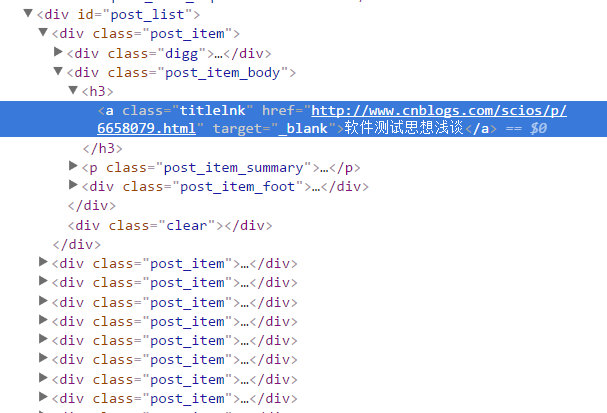
比如我们这里解析博客园首页文章列表,查看博客园首页列表html,如图所示:
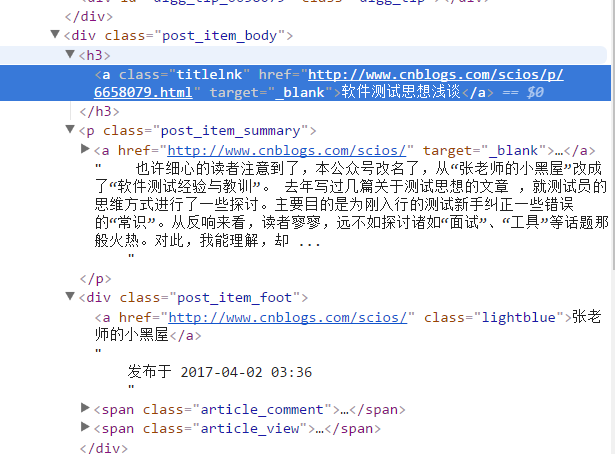
抓取所有文章的名称
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threading.Tasks;using HtmlAgilityPack;namespace HtmlAgilityPackDemo{ class Program { static void Main(string[] args) { //初始化网络请求客户端 HtmlWeb webClient = new HtmlWeb(); //初始化文档 HtmlDocument doc = webClient.Load("http://www.cnblogs.com/"); //查找节点 HtmlNodeCollection titleNodes = doc.DocumentNode.SelectNodes("//a[@class='titlelnk']"); if (titleNodes != null) { foreach (var item in titleNodes) { Console.WriteLine(item.InnerText); } } Console.Read(); } }} 输出

记得之前自己写过一个小工具,当时还是自己写的正则来匹配的,和这个组件相比确实很麻烦。
在上面的代码中,有[@class='xxx']的设置,它是根据html标签的属性查找node,当然你也可以进行其它的设置,如根据id查找,你可以这样写h3[@id='xxxx']。
获取节点的内容,可以通过下面的方式获取
node.InnerText node.InnerHtml node.OuterHtml